

克雷西 发自 凹非寺
量子位 | 公众号 QbitAI
斯坦福吴佳俊团队,给机器东谈主设想了一套拼装宜家产物的视频教程!
具体来说,团队提议了用于机器东谈主的大型多模态数据集IKEA Video Manuals,已入选NeurIPS。

数据集涵盖了6大类IKEA产物,每种产物都包含完满的3D模子、拼装说明书和本色拼装视频。
而且远离精采,拆解出的安装子表情多达1000多个。

作家先容,该数据集初次终明显拼装教唆在果然场景中的4D对王人,为议论这一复杂问题提供了弘远基准。
着名科技博主、前微软政策议论者Robert Scoble说,有了这个数据集,机器东谈主将不错学会我方拼装产物。

团队成员、斯坦福拜谒学者李曼玲(Manling Li)示意,这是空间智能限度的一项弘远责任:
这项责任将拼装缱绻从2D鼓动到3D空间,通过纠合底层视觉细节,处理了空间智能议论中的一个主要瓶颈。

1120个子表情胪陈拼装历程
IKEA Video Manuals数据聚拢,涵盖了6大类36种IKEA产物,检朴单的凳子到复杂的柜子,呈现了不同难度的拼装任务。

每一款产物,都包括以下三种模态:
安装说明书,提供了任务的举座领会和重要表情;果然拼装视频,展示了清闲的拼装历程;3D模子,界说了部件之间的精准空间络续。况兼这三种模态并非浅易地堆砌在一齐,作家通过对视频和操作表情的拆解,将三种模态进行了精采的对王人。
举个例子,在这么一条对于长凳的数据当中,包含了其基本大约、视频信息、重要帧信息,以及安装表情。
从下图中不错看出,安装表情当中有主要表情和子表情的远离,还标注了对应的视频位置。
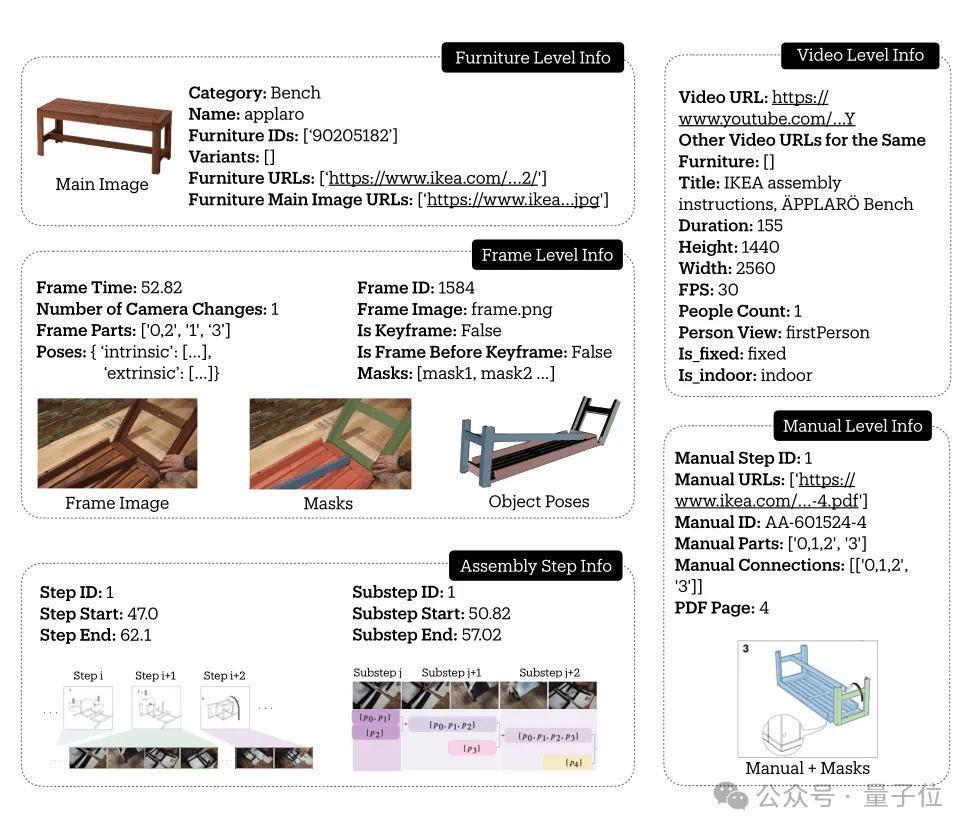
通盘这个词数据聚拢,共包含了137个手册表情,凭据安装视频被细分为了1120个具体子表情,捕捉了完满的拼装历程。
况兼通过6D Pose追踪,每个部件的空间轨迹都被精准记载,最终在视频帧、产物拼装说明书和3D模子之间成就了密集的对应络续。
时空信息精采标注IKEA Video Manuals数据集是在IKEA-Manual和IKEA Assembly in the Wild(IAW)两个数据集的基础上成就的。
其中,IKEA-Manual数据集提供了模子特殊对应说明书,IAW则包含了多数用户拼装宜家产物的视频片断。
这些视频来自90多个不同的环境,包括室表里场景、不同光照条款,果然反应了产物拼装的各类性。

与在现实室环境下收集的数据比较,这些果然视频带来了更丰富的挑战:
部件频繁被手或其他物体艰涩;相似部件识别(如四条一模一样的桌子腿);录像机频繁挪动、变焦,带来参数揣度的艰苦;室表里场景、不同光照条款下的各类性。
为了取得高质地的标注,派遣果然视频带来的挑战,议论团队成就了一套可靠的标注系统:
识别并标注相机参数变化的重要帧,确保片断内的一致性;联接2D-3D对应点和RANSAC算法进行相机参数揣度;通过多视角考据和时序抑止保证标注质地。
最初,议论者们最初界说了一套端倪化的装置历程描述框架,将通盘这个词装置历程分为表情、子表情和视频帧等多个层级。
作家最初从IAW数据聚拢提真金不怕火每个手动表情的视频片断,并将每个视频片断领会为更小的停止(子表情)。
对于每个子表情,作家以1FPS的速率采样视频帧,并在每个子表情的第一帧中标注坐褥物部件。
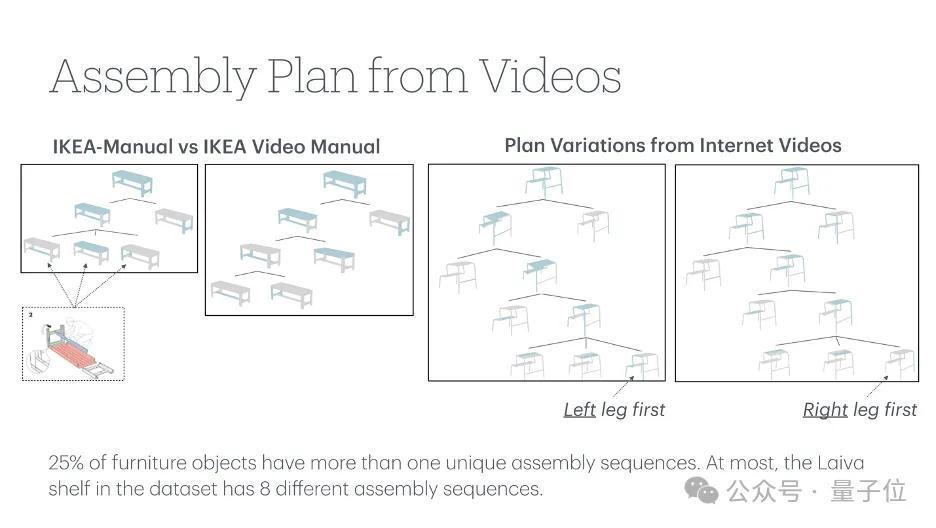
为了在通盘这个词拼装视频中对产物部件进行追踪,作家还在采样帧中为3D部件审视了2D图像分割掩码。
为了促进审视历程,议论团队拓荒了一个清楚援手2D和3D信息的Web界面,同期该界面还可基于Segment Anything Model(SAM)模子进行交互式掩码审视。

标注历程中,标注东谈主员会在3D模子上选中零件,然后在2D视频帧上教唆其梗概位置,并将其输入到SAM模子中以及时生成2D分割掩码。
为了处理SAM在提真金不怕火具有相似纹理的部分之间或低光区域的鸿沟方面的固有局限,作家还允许标注东谈主员使用画笔和橡皮擦器用进行手动调理。
此外,作家还要揣度视频中的相机参数,为此议论者们最初东谈主工记号出视频帧中可能出现相机率领(如焦距变化、切换视角等)的位置,然后标注出视频帧和3D模子之间的2D-3D对应重要点。
终末,联接这两类标注信息,议论者们使用PnP (Perspective-n-Point)算法揣度出每段视频的相机内参数,得到相机参数的动手揣度后,诳骗交互式器用来细化每个视频帧中零件的6D姿态。
空间模子智商评估基于IKEA Video Manuals数据集,团队设想了多个中枢任务来评估现时AI系统在纠合和实行产物拼装,以及空间推理(spatial reasoning)方面的智商。
最初是基于3D模子的分割(Segmentation)与姿态揣度 (Pose Estimation)。
此类任务输入3D模子和视频帧,要求AI准确分割出特定部件区域,并揣度其在视频中的6解放度姿态。

△上:基于3D模子的分割,下:基于3D模子的姿态揣度
现实测试了最新的分割模子(CNOS, SAM-6D)和姿态揣度模子(MegaPose)。
分析发现,它们在以下场景说明欠安:
艰涩问题:手部艰涩、近距离拍摄导致部分可见、艰涩引起的深度揣度差错;特征缺失:浮泛纹理的部件难以分割、对称部件的主义难以判断;特别拍摄角度(如俯瞰)导致的程序误判。
△上:艰涩问题,左下:特征缺失,右下:特别角度
第二类任务是视频指标分割,作家对比测试了两个最新的视频追踪模子SAM2和Cutie。
效果清楚,在果然拼装场景中,这些模子相同濒临着三大挑战。
一是相机的率领,可能导致指标丢失。

二是难以区分外不雅相似的部件(如多个辩论的桌腿)。

终末,保抓长技巧追踪的准确度也存在一定难度。
第三类任务,是基于视频的表情拼装。
团队提议了一个立异的拼装系统,包含重要帧检测、部件识别、姿态揣度和迭代拼装四个表情。
现实吸收两种成就:
使用GPT-4V自动检测重要帧:效果不睬思,Chamfer Distance达0.55,且1/3的测试视频未能完成拼装;使用东谈主工标注的重要帧:由于姿态揣度模子的局限性,最终Chamfer Distance仍达0.33。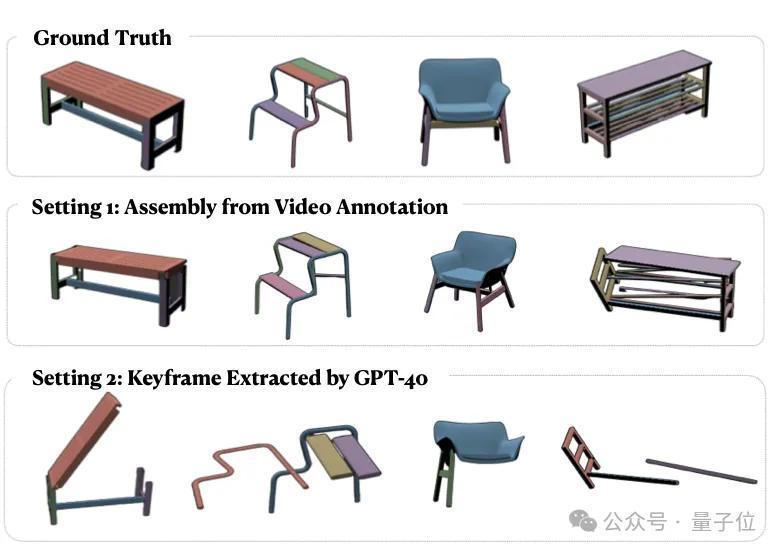
这些现实效果揭示了现时AI模子的两个重要局限:
视频纠合智商不及:现时的视频模子对时序信息的分析仍然较弱,通常停留在单帧图像分析的层面;空间推理受限:在果然场景的复杂条款下(如光照变化、视角蜕变、部件艰涩等),现存模子的空间推明智商仍显不及。作家简介本技俩第一作家,是斯坦福大学经营机科学硕士生刘雨浓(Yunong Liu)现在在斯坦福SVL现实室(Vision and Learning Lab),由吴佳俊教会率领。

她本科毕业于爱丁堡大学电子与经营机科学专科(荣誉学位),曾在德克萨斯大学奥斯汀分校从事议论实习。
斯坦福大学助理教会、清华姚班学友吴佳俊,是本技俩的率领教会。

另据论文信息清楚,斯坦福大学博士后议论员刘蔚宇(Weiyu Liu),与吴佳俊具有同等孝顺。

此外,Salesforce AI Research议论主任Juan Carlos Niebles,西北大学经营机科学系助理教会、斯坦福拜谒学者李曼玲(Manling Li)等东谈主亦参与了此技俩。


其他作家情况如下:

技俩主页:
https://yunongliu1.github.io/ikea-video-manual/论文地址:https://arxiv.org/abs/2411.11409— 完 —
量子位 QbitAI · 头条号签约
体恤咱们,第一技巧获知前沿科技动态